PodWorkers是最终“同步”pod状态的一块逻辑,
“同步”在这里的含义是:确保kubelet所在节点的Pod状态和etcd中的状态一致,该增加的增加,该删除的删除,该更新的更新。
“同步”动作的触发有几个方式:
(1)通过文件、apiserver、http方式监听到的变化
(2)定时器触发,例如每隔10s
PodWorkers的入口是UpdatePod
1 | type podWorkers struct { |
简单的示意图
PodWorkers是最终“同步”pod状态的一块逻辑,
“同步”在这里的含义是:确保kubelet所在节点的Pod状态和etcd中的状态一致,该增加的增加,该删除的删除,该更新的更新。
“同步”动作的触发有几个方式:
(1)通过文件、apiserver、http方式监听到的变化
(2)定时器触发,例如每隔10s
PodWorkers的入口是UpdatePod
1 | type podWorkers struct { |
简单的示意图
参考前一篇文章
目前的docker已经不是之前的docker了,技术栈进行了分层。
docker cli -> dockerd -> containerd -> oci implementation
OCI规范,简单来说,包含容器规范和镜像规范,具体参考:
link
由于引入了OCI,我们可以近乎透明无缝的替换 “docker run”命令 之下的具体实现。
根据自己业务场景的需求,可以选择高性能的容器运行时,也可以选择性能不那么高但安全性更好的运行时。
目前符合OCI规范的容器运行时有:
目前docker默认使用的容器运行时runc。
docker命令行有一个参数:runtime,可以制定底层的容器运行时,如
1 | docker run --runtime=runc hello-world |
runc官方有一个实例,介绍如何用runc运行一个容器
1 | EXAMPLE: |
网上有一个runc 和 runv 运行示例的文章,参考: 链接
说回到kubernetes,k8s抽象出了一个CRI接口。
kubelet 通过该接口与底层不同的容器运行时进行交互,从而实现解耦。
其中的关系如下图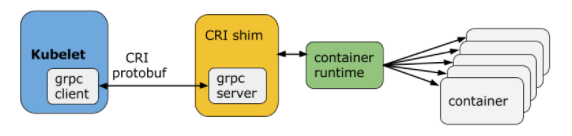
kubelet通过gRPC方式调用CRI的相关接口,CRI shim是该接口的一个实现。
kubelet有一个选项“–container-runtime”,
默认为docker,可以理解为非CRI模式。
设置为remote的时候,可以认为是启用了CRI模式,通过另外一个选项
–container-runtime-path-endpoint=
kubelet会通过指定的CRI地址来进行容器的管理。
这个图看着可能会比较清楚
Java APNS(notnoop)
https://github.com/notnoop/java-apns
dbay-apns-for-java
https://github.com/RamosLi/dbay-apns-for-java
Turo的pushy
https://github.com/relayrides/pushy
项目中有一个需求:给线程池提交任务的时候,如果任务队列已满,需要ThreadPoolExecutor.execute调用阻塞等待。google了相关的资料,记录在这里,供有同样需求的同行参考。
ThreadPoolExecutor相关的几个点:
(1)execute提交任务的时候,会调用指定队列的offer方法,如果offer方法返回失败,则表示队列已满。如果此时,corePoolSize < maximumPoolSize 会发起新的线程执行新提交的任务;如果 corePoolSize == maximumPoolSize, 则任务提交失败,会调用RejectedExecutionHandler处理
(2)java提供了四个内置的RejectedExecutionHandler, 如
1 | /** |
解法1: 重写队列的offer方法,让其变为一个阻塞调用
使用这种方法时,线程数最多只能到corePoolSize个,相当于maximumPoolSize的设置无效;
1 | /** |
解法2: 基于java信号量
1 | public class BoundedExecutor { |
本文跟踪一下kubelet启动过程中,参数的默认值是如何注入的。
我们知道,为了启动kubelet服务,首先要构造kubelet的配置对象,即kubeletconfig.KubeletConfiguration结构体,
1 | // NewKubeletCommand creates a *cobra.Command object with default parameters |
1 | // NewKubeletConfiguration will create a new KubeletConfiguration with default values |
构造kubelet schmea的函数如下:
1 | // NewSchemeAndCodecs is a utility function that returns a Scheme and CodecFactory |
最下层的初始化函数如下:
1 | func SetDefaults_KubeletConfiguration(obj *kubeletconfigv1beta1.KubeletConfiguration) { |
最后看下,scheme的具体代码
1 | // Scheme defines methods for serializing and deserializing API objects, a type |
总的调用链路大概如下:
options.NewKubeletConfiguration() -> kubeletscheme.NewSchemeAndCodecs()(完成kubeletSchema的构建,包括类型的注册,初始化函数的注册) -> scheme.Default() -> SetDefaults_KubeletConfiguration()